How to Stop Silent Pipeline Failures From Swallowing Your IIoT Data
When your pipeline fails, every dropped message is data you'll never get back, until now
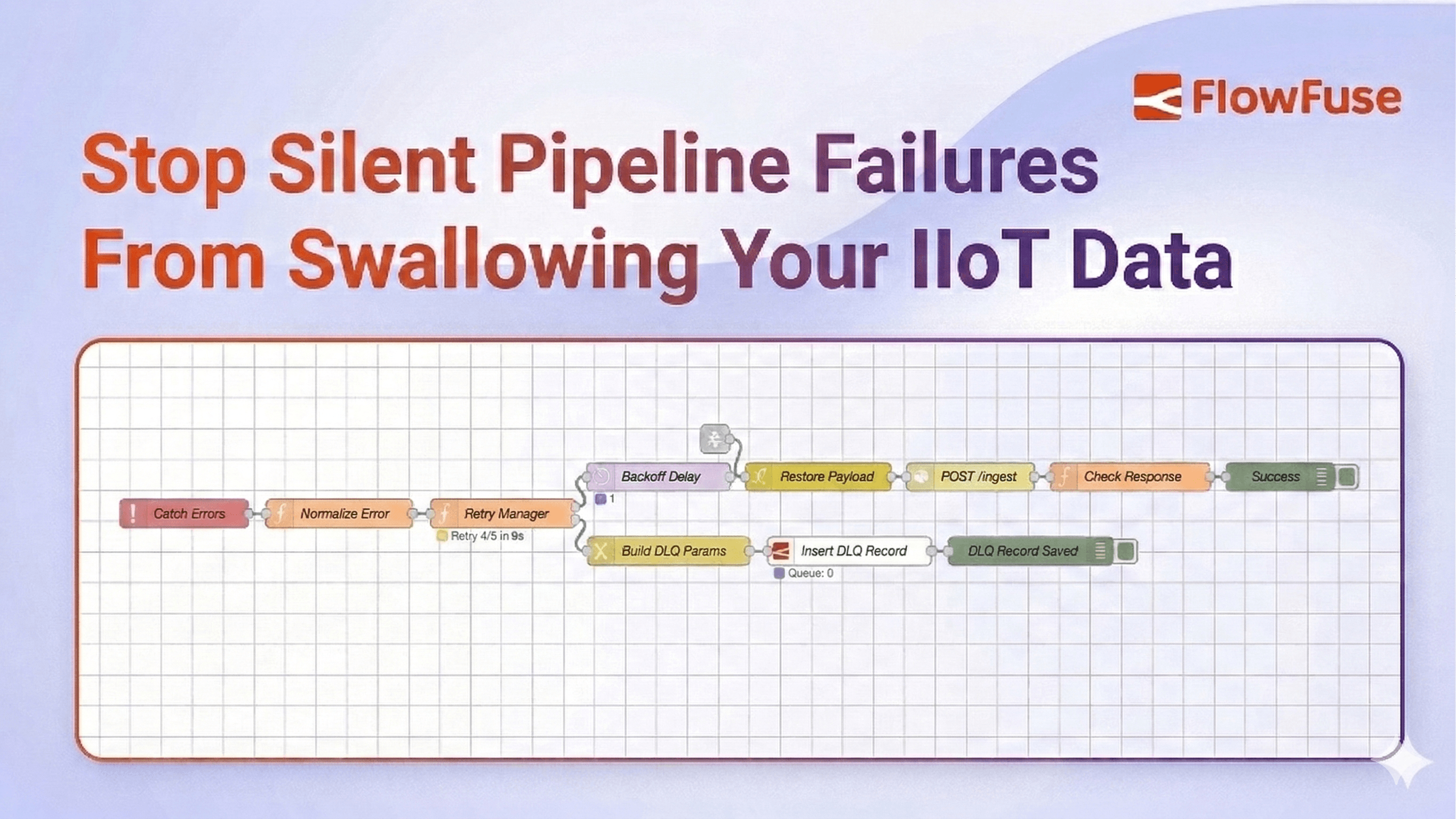
Somewhere in your IIoT pipeline, a message just failed. You don't know which one. You don't know when. And unless you have a Dead Letter Queue, you never will.
In industrial environments, failure is not the exception. It is the contract. Networks partition. APIs rate-limit. A sensor alert fires at the wrong moment and vanishes without a trace. And unlike consumer applications, missed messages in manufacturing have a real cost.
That cost is invisible by default. No error surface. No audit trail. Just data that was there and then wasn't. FlowFuse changes that. It gives your IIoT pipelines the production-grade tooling they need to handle failure the right way: catch it, retry it, and preserve everything that couldn't be recovered so you can act on it later.
This guide shows you how to build exactly that. You will walk away with a production-ready pattern for catching failed messages, retrying them with exponential backoff, and routing the unrecoverable ones into a Dead Letter Queue where they can be inspected, replayed, or discarded on your terms.
What Is a Dead Letter Queue?
A Dead Letter Queue is a holding area for messages that could not be delivered. When a message fails processing and has no path forward, it gets routed to the DLQ instead of being dropped or causing your flow to crash.
A message ends up in a DLQ for four reasons. It exceeded the maximum number of retry attempts. It is malformed and cannot be parsed. The target system is permanently unavailable. Or a business rule explicitly rejected it.
The value of a DLQ is not just storage. It is observability. Every failed message arrives with its full payload, error reason, retry history, and timestamps intact. You know exactly what failed, when it failed, and how many times it was attempted before giving up. That information is what makes recovery possible.
Without a DLQ, failed messages disappear silently. With one, failure becomes something you can inspect, act on, and fix.
The Retry Pattern: Exponential Backoff
Before a message earns its place in the DLQ, you should try, and try again. But naive retries are dangerous. Hammering a failing service every 100ms does not give it time to recover. It makes things worse for everyone.
The industry standard is exponential backoff with jitter:
delay = min(base * 2^attempt, max_delay) + random_jitter
| Attempt | Base Delay | With Jitter (approx.) |
|---|---|---|
| 1 | 1s | 1.2s |
| 2 | 2s | 2.5s |
| 3 | 4s | 4.1s |
| 4 | 8s | 8.9s |
| 5 | — | → DLQ |
The jitter prevents the thundering herd problem, where every failed client retries at exactly the same moment and overloads the service all over again.
Building It
In this section, we'll build this pattern in FlowFuse step by step.
FlowFuse is the Industrial Application Platform that connects any machine or system, collects data across any protocol, and lets you act on it at production scale, with enterprise features like role-based access control, centralized device management, audit logging, and team collaboration built in. It also includes FlowFuse Tables, a built-in database service that gives all your instances a single shared DLQ, so every failed message across your entire fleet lands in one place, visible and queryable from anywhere. Contact us to get started.
The architecture has five components:
- Retry state initializer
- Catch node for centralized error handling
- Retry manager with exponential backoff
- Delay node for controlled retries
- Dead Letter Queue backed by FlowFuse Tables
Here's how they connect:
flowchart TD
A[Input] --> B[Process]
B --> C[Success Handler]
B -->|on error| D[Retry Manager]
D -->|within max retries| E[Delay]
E --> B
D -->|max retries exceeded| F[Dead Letter Queue]
linkStyle default stroke:#4F46E5,stroke-width:2px
style A fill:#ffffff,color:#4B5563,stroke:#4F46E5
style B fill:#ffffff,color:#4B5563,stroke:#4F46E5
style C fill:#ffffff,color:#4B5563,stroke:#4F46E5
style D fill:#ffffff,color:#4B5563,stroke:#4F46E5
style E fill:#ffffff,color:#4B5563,stroke:#4F46E5
style F fill:#ffffff,color:#4B5563,stroke:#4F46E5
Every step below maps directly to one part of that diagram. Follow it in order.
Step 1: Initialize Retry State
This function node runs once when a fresh message enters the pipeline. It attaches retry metadata to msg so every downstream node knows where the message stands.
- Drag a function node onto the canvas.
- Double-click it to open its settings.
- In the Name field, enter
Init Retry State. - In the Function tab, paste the following code:
msg._originalPayload = RED.util.cloneMessage(msg.payload);
if (!msg._retry) {
msg._retry = {
attempts: 0,
maxAttempts: 5,
lastError: null,
originalTimestamp: new Date().toISOString(),
topic: msg.topic
};
}
return msg;- Click Done.
Two things are happening here worth noting. First, msg._originalPayload saves a deep clone of the original payload using RED.util.cloneMessage before anything touches it. A plain assignment (= msg.payload) would only copy a reference. If a downstream node mutates the object in place, the saved copy changes too. cloneMessage ensures the DLQ always holds the payload exactly as it arrived. Some nodes, like the HTTP Request node, also overwrite msg.payload with their response body, so this clone is what gets stored in the DLQ later. Second, the if (!msg._retry) check ensures initialization only runs on a fresh message. When the retry loop sends the message back through, this block is skipped entirely and the existing retry state is preserved. The underscore prefix on msg._retry also protects it from being overwritten by processing nodes.
Step 2: Add a Catch Node
The catch node monitors your processing nodes and intercepts any message that causes an error, routing it to the retry logic instead of letting it disappear.
Scoping it to All nodes is tempting but dangerous. If any node in the retry infrastructure itself throws, for example the Retry Manager calling node.error(), the catch node will intercept it and feed it back into the retry loop, creating an infinite loop. Scoping it explicitly to your processing nodes prevents this.
- Drag a catch node onto the canvas.
- Double-click it to open its settings.
- In the Name field, enter
Catch Errors. - Set Catch errors from to
Selected nodes. - Select only the nodes where real failures can occur. In practice, these are the nodes that talk to the outside world: MQTT nodes, HTTP request nodes, database nodes, WebSocket nodes, or anything that reaches beyond the flow itself. Taking the example flow provided at the end of this guide, that means selecting the HTTP Request node and the Check Response function node.
- Click Done.
Next, add a normalization step between the catch node and the retry manager. Built-in nodes sometimes attach msg.error as an object rather than a string, which causes problems downstream. This function node converts it to a consistent string format.
- Drag a function node onto the canvas.
- Double-click it to open its settings.
- In the Name field, enter
Normalize Error. - In the Function tab, paste:
msg.retry = msg._retry;
if (typeof msg.error === 'object') {
msg.error = msg.error.message || JSON.stringify(msg.error);
}
msg.error = msg.error || 'Processing failed';
return msg;- Click Done.
- Wire the catch node output to the Normalize Error input.
Step 3: Add the Retry Manager
This is the decision node. It increments the attempt count, calculates the backoff delay, and routes the message either back into the pipeline for another try or forward to the DLQ if retries are exhausted.
- Drag a function node onto the canvas.
- Double-click it to open its settings.
- In the Name field, enter
Retry Manager. - Go to the Setup tab and set Outputs to
2. This gives the node two output ports, one for retrying and one for the DLQ. - Go to the Function tab and paste:
const MAX_ATTEMPTS = msg.retry.maxAttempts || 5;
const BASE_DELAY_MS = 1000;
const MAX_DELAY_MS = 30000;
msg.retry.attempts += 1;
msg.retry.lastError = msg.error || 'Unknown error';
msg.retry.lastAttemptAt = new Date().toISOString();
// keep _retry in sync
msg._retry = msg.retry;
if (msg.retry.attempts >= MAX_ATTEMPTS) {
msg.retry.exhausted = true;
msg.dlq = {
reason: 'Max retries exceeded',
attempts: msg.retry.attempts,
lastError: msg.retry.lastError,
deadAt: new Date().toISOString()
};
return [null, msg];
}
const exponential = BASE_DELAY_MS * Math.pow(2, msg.retry.attempts - 1);
const jitter = Math.random() * 1000;
const delay = Math.min(exponential + jitter, MAX_DELAY_MS);
msg.delay = Math.round(delay);
node.status({
fill: 'yellow',
shape: 'ring',
text: `Retry ${msg.retry.attempts}/${MAX_ATTEMPTS} in ${Math.round(delay / 1000)}s`
});
return [msg, null];- Click Done.
- Wire the Normalize Error output to the Retry Manager input.
return [msg, null] sends the message out of Output 1 (retry path). return [null, msg] sends it out of Output 2 (DLQ path). No switch node is needed. The routing is built into the return statement.
Step 4: Add the Delay Node
The delay node holds the message for the calculated backoff period before it re-enters the pipeline. Without this, retries fire instantly and you are hammering an already-struggling service.
- Drag a delay node onto the canvas.
- Double-click it to open its settings.
- In the Name field, enter
Backoff Delay. - Set Action to
Delay each message. - Set For to
Override delay with msg.delay. This tells the node to use the backoff value the Retry Manager calculated rather than a fixed duration. - Click Done.
- Wire Retry Manager Output 1 to Backoff Delay input.
Each pass through the loop, the delay gets longer. Roughly 1 second on the first retry, 2 seconds on the second, 4 on the third, and so on. When the Retry Manager decides retries are exhausted, it stops sending to Output 1 entirely and routes to Output 2 instead, ending the loop.
Wire Backoff Delay output to your processing node input. This completes the retry loop.
Step 5: Set Up the DLQ Handler
When a message reaches this stage, retries are finished. The goal now is to preserve everything: the original payload, the error reason, how many attempts were made, and the timestamp. That context is what makes later recovery possible. Without a persistent store, that context disappears the moment the flow restarts, the device reboots, or the pipeline moves on to the next message. And in a multi-instance deployment, you need a store that is accessible across every instance in your fleet, not just the device the failure happened on.
FlowFuse Tables gives you exactly that: a managed PostgreSQL database that connects directly to your flows with no credentials to configure and no external infrastructure to manage, making it the right storage layer for a production DLQ.
Note: FlowFuse Tables requires an Enterprise plan.
5a: Create the DLQ Table
- In FlowFuse, go to Team Settings and enable the Tables feature for your team.
- Once enabled, drag a Query node from the FlowFuse category onto the canvas.
- The Query node is pre-configured to connect to your FlowFuse-managed database automatically. No credentials needed.
- Paste the following into the Query field:
CREATE TABLE IF NOT EXISTS "dlq" (
"id" TEXT PRIMARY KEY,
"topic" TEXT,
"payload" TEXT,
"attempts" INTEGER,
"last_error" TEXT,
"captured_at" TEXT
)- Connect an Inject node set to run once on deploy to the Query node input.
- Click Done and deploy.
Tip: If you prefer, you can also create the table directly from the Tables section in the FlowFuse navigation without writing any SQL.
5b: Build the Insert Flow
- Drag a change node onto the canvas and name it
Build DLQ Params. - Add the following rules:
| Action | Target | Value type | Value |
|---|---|---|---|
| Set | msg.queryParameters |
JSON | {} |
| Set | msg.queryParameters.id |
msg | _msgid |
| Set | msg.queryParameters.topic |
msg | retry.topic |
| Set | msg.queryParameters.payload |
JSONata | $string(_originalPayload) |
| Set | msg.queryParameters.attempts |
msg | retry.attempts |
| Set | msg.queryParameters.last_error |
msg | retry.lastError |
| Set | msg.queryParameters.captured_at |
JSONata | $now() |
- Drag a Query node from the FlowFuse category onto the canvas and name it
Insert DLQ Record. - Paste the following SQL:
INSERT INTO "dlq" ("id", "topic", "payload", "attempts", "last_error", "captured_at")
VALUES ($id, $topic, $payload, $attempts, $last_error, $captured_at)
ON CONFLICT ("id") DO UPDATE SET
"attempts" = EXCLUDED."attempts",
"last_error" = EXCLUDED."last_error",
"captured_at" = EXCLUDED."captured_at"- Wire Retry Manager Output 2 to Build DLQ Params, then Build DLQ Params to Insert DLQ Record.
ON CONFLICT DO UPDATE ensures a message that appears multiple times does not create duplicate rows. It updates cleanly on the same id.
Putting It All Together: Simulation
The best way to understand the pattern is to watch it work. This simulation models a temperature sensor publishing readings to an HTTP API every 5 seconds. The mock API is deliberately configured to fail 80% of the time so you can watch the full cycle in action: messages attempting delivery, retrying with increasing delays, and after 5 failed attempts landing permanently in FlowFuse Tables.
Import the flow below directly into FlowFuse. It contains everything: the sensor data simulator, the mock API, the retry logic, the DLQ handler, and a query button to inspect what landed in the database.
Note: In the simulation, the retry state initialization from Step 1 is folded directly into the Simulate Reading function node rather than existing as a separate node. In a real deployment you would keep them separate as described in the tutorial.
Closing Thoughts
Every message your system drops was someone's data. A sensor reading that never made it. A transaction that silently disappeared. An event that the downstream system never knew existed. In most IIoT deployments these failures are invisible. No record, no alert, no way to recover what was lost.
That is the problem this pattern solves.
A Dead Letter Queue does not make your system more reliable. Reliability comes from good infrastructure, careful design, and redundancy. What a DLQ gives you is honesty. An honest record of every message that could not be delivered, with enough context to understand why, and enough structure to do something about it.
You deploy it once and it works quietly in the background until the moment you need it.
And you will need it. Not because your flows are poorly built, but because distributed systems fail. APIs go down. Networks drop. Services timeout at the worst possible moment. The question has never been whether that happens. It is whether you are ready when it does.
Now you are.
Stop losing data you'll never get back. Contact us to build a fault-tolerant IIoT pipeline that catches every failure before it disappears.
About the Author
Sumit Shinde
Technical Writer
Sumit is a Technical Writer at FlowFuse who helps engineers adopt Node-RED for industrial automation projects. He has authored over 100 articles covering industrial protocols (OPC UA, MQTT, Modbus), Unified Namespace architectures, and practical manufacturing solutions. Through his writing, he makes complex industrial concepts accessible, helping teams connect legacy equipment, build real-time dashboards, and implement Industry 4.0 strategies.